TIRG
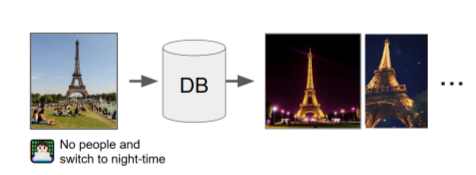
《Composing Text and Image for Image Retrieval - An Empirical Odyssey》是2018年被CVPR收录的一篇论文。主要研究的问题是带有修改任务的图像检索。例如。我们可能提供一张埃菲尔铁塔照片,然后想让系统查询出没有人并且是夜间的照片。
这个问题可被看作:
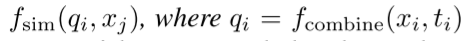
本文作者主要有三点贡献
- 系统研究了图像检索的特征合成,提出了一种新的方法。
- 创造了一种新的数据集CSS。
- 算法提升了在Fashion-200K和MIT-States数据集上的检索效果。
方法
文中提出的方法是在空间维度,建立图片和文本结合的嵌入空间,使用ResNet提取图片卷积特征fimg(x) =$\phi$,使用LSTM提取文本特征text(t) =$\phi$t,并结合二者$\phi$xt=fcombine($\phi$x,$\phi$t)。

已有方法
- Only 图像
- Only 文本
- 将\(\phi\)x,\(\phi\)t使用MLP方法进行连接计算。本文中使用2层MLP进行残差计算。
- 先使用LSTM编码图片特征,再逐步加入文本,最后生成\(\phi\)xt。(Show and Tell)
- 将文本嵌入作为转换矩阵对图片进行变换。
- 使用哈希编码文本特征,并将其应用于图片特征,用于替换CNN最后的全连接网络,最终输出图片和文本结合的表征。
- 寻找相关性是图片问答中常用的方法,从卷积网络中提取2d的图片特征,然后用串联的方式将文本特征与2d图片中特征提取的2个局部特征相结合,送入MLP,对输出的表征取均值得到最终表征。
- FiLM将文本特征注入CNN网络,处理CNN的每一层数据,使用文本对图片特征做简单地仿射变换。
本文方法
使用残差网络和门网络结合的办法。称为TIRG。 总的公式如下:
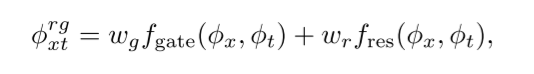
门控公式如下:

残差网络公式如下:

度量方法
图像文本查询表征:
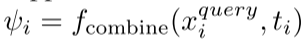
正例表征:

训练时选择一个正例和k-1个反例进行训练。minibatch为B,重复M次。利用softmax+交叉熵计算损失。如下:

当k=2时,loss公式可重写为:

如果k=2,我们选择M=B-1,这样每一个样例i都可以和所有的可能反例为一对。
选择更大的K,每一个样例都能与更多的反例比较,这样取M=1,loss公式可简化为:

当K增大时,会使得实验更有识别力,识别更迅速,也更容易导致过拟合。因为fashion200k数据集更难被覆盖,所以选择K=B。其余两个数据集选择K=2.
实验
作者使用了fashion200k,MIT-States,CSS三个数据集。 在fashion200k和MIT-states中,作者修正了最后的fc层,让特征更加全局和抽象。 在CSS中修正了最后的2d特征图,捕捉更低维度和空间变化。