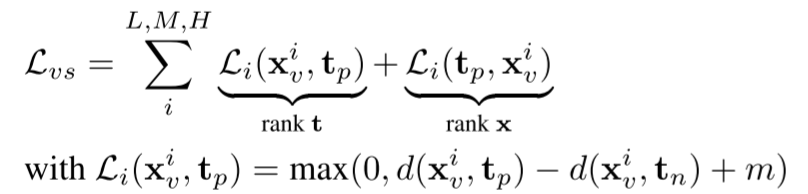VAL
《Image Search with Text Feedback by Visiolinguistic Attention Learning》是2020年被CVPR收录的一篇论文。主要研究的问题是带文本反馈的图片检索。例如给一张黑色的图片,文本反馈是想要一个粉色的同款。
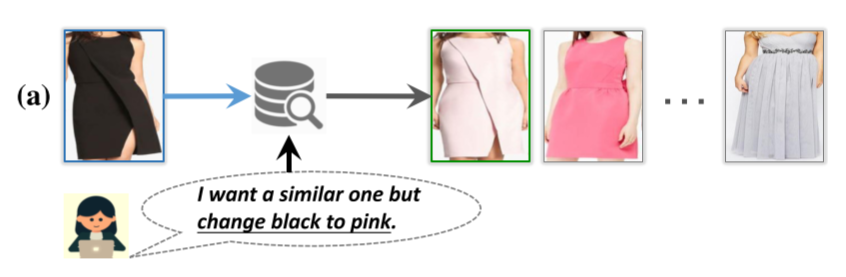
本文更加关注文本反馈,因为文本可以是属性描述,也可以是自然语言表达。
本文作者主要有两点贡献
- 采用VAL结构。VAL是多重复合的transformer。
- 采用fashion200k,fashionIQ,shoes三个数据集
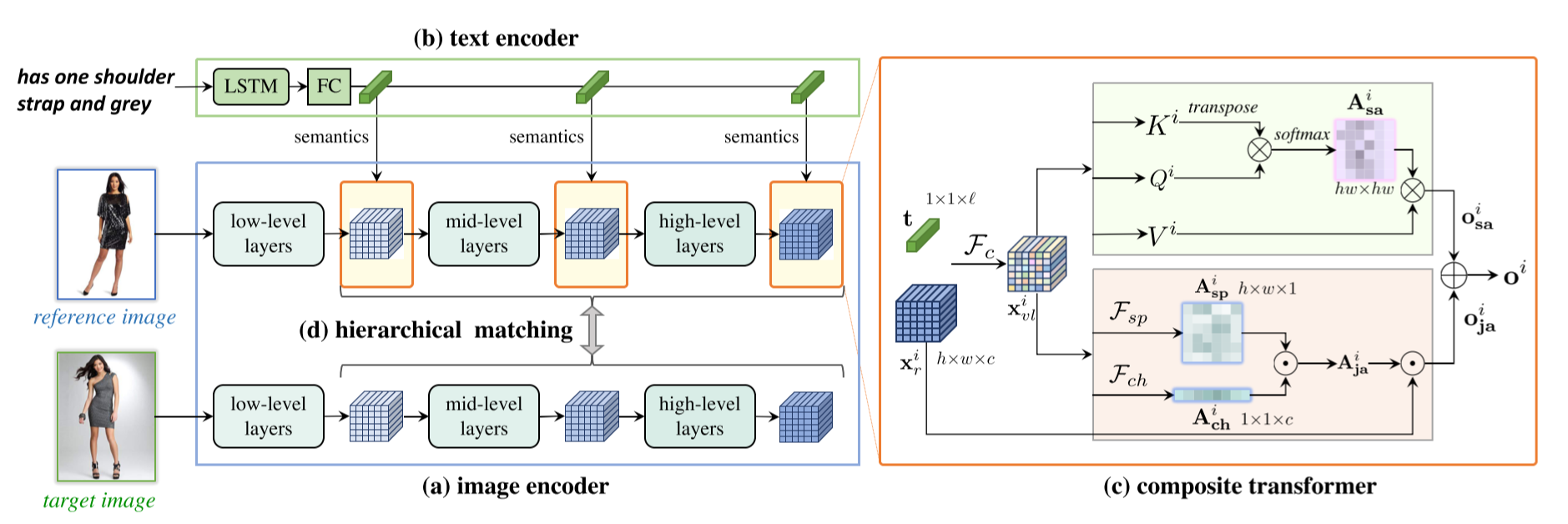
图像文本表征
采用标准CNN学习图像表征,从low,mid,high-level 3个level提取,建造一个特征金字塔,表示如下:
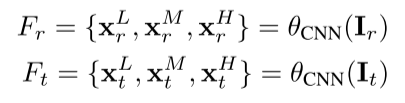
其中$F_{r}$ 是参考图像,$F_{t}$是目标图像。
采用LTSM来学习文本表征,在LSTM后加入max-pooling和linear projection layer。
复合transformer
将文本表征与图像表征融合表示:
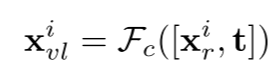
其中$i$表示第$i$个图像level,$F_{c}$是MLP
自注意力transformation
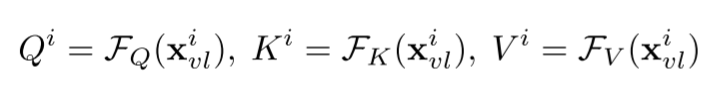
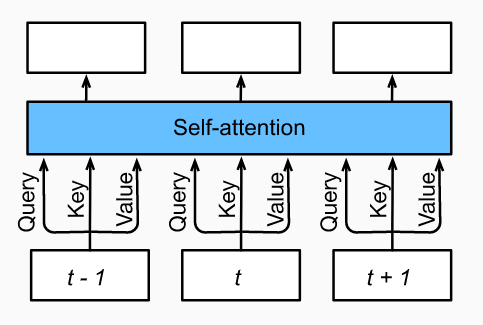
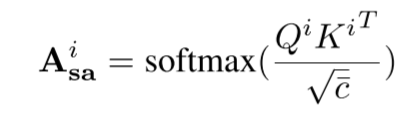
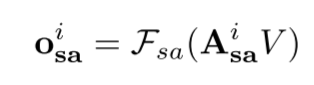
第二个表达式即self-attention函数,第三个表达式计算output
Joint-Attentional Preservation
自注意力transformation捕获了用于特征变换的非局部相关性,但是没有确切表明参考图像特征如何保持与输入图像的的相似性。因此引入Joint-Attentional Preservation
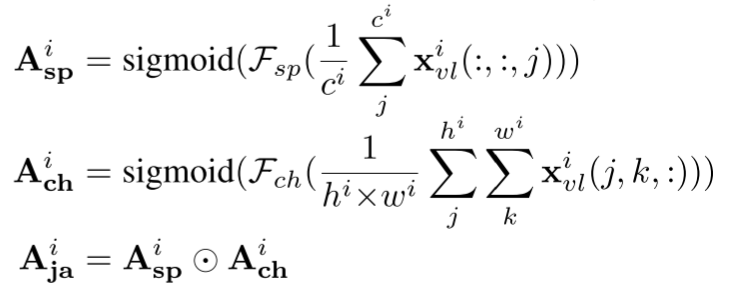
$F_{sp}$,$F_{ch}$学习空间和通道。
$A^{i}_{ja}$是joint-attention 矩阵,动态调整保留参考图像的强度。
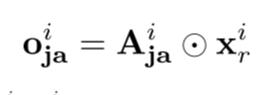
最终的输出表达时如下:
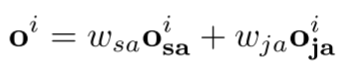
分层匹配
采用两种损失,两级层次,分别计算图像和图像,图像和语义的损失
确保目标特征和复合特征的高相似度,采用图像与图像损失表达式如下:
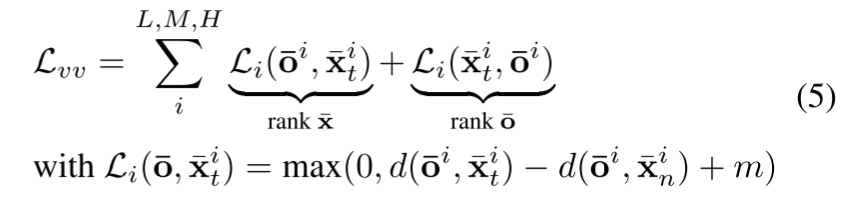
为了进一步将学习到的表征与期望的语义联系起来,采用辅助的图像与语义损失表达式如下: